MiniRobotLanguage (MRL)
AIC.Ask_with_History
Ask or instruct the most advanced Open AI models using a history-Array and expect Return.

In the WEB-UI, ChatGPT uses the history of previous answers to generate a new answer.
Using this Command you can do exactly this also.
Intention
The AIC.Ask_with_History Command allows you to add a complete "Chat History" to the prompt, in the same way as if you would have been chatting with the AI in the Chat-Window.
This way you can reconstruct and get the same Answers that you may have gotten while chatting with the AI (at low temperature values, else there is a high random factor).
The AIC.Ask_with_History Command is the most advanced AI-Command to send a Question or Instruction to the most advanced Open AI models and receive an answer.
Using this Command you can achieve the same results like if you chat with the AI in a Browser Window.
You can attach a "chat history" to the Prompt, which is done using the new Array-Commands.
You will need to get an API-Key here: AI - Artificial Intelligence Commands before being able to use this Command.
Use the AIC.Set_Model_Chat Command to specifying the OpenAI model you want to use for chat-based conversations.
There are multiple other Commands which can be used to change the environment for the AI.
Once all preconditions are set, the usage of this Command is as simple as:
'#SPI:NoAPIKey
' Set OpenAI API-Key from the saved File
AIC.SetKey|File
' Set Model
AIC.SetModel_Chat|3
' Set Model-Temperature
AIC.Set_Temperature|0.6
AIC.SetMax_Token|300
' Using the ARR.-Command we buld a Chat history
'Each Array element must constist of 2 Parts:
'<Role>:<Content>
' You can use as many Array Elements as you like, the Array is "Auto-Dim"
'
' <Array-No.>|<Array-Element No.>|<Text to assign to the Array Element>
'
ARR.Set|1|0|system:You are a technical advisor. Your name is Paul.
ARR.Set|1|1|user:What is 1+1?
ARR.Set|1|2|assistant:Hallo, I am Paul and 1+1 is 2.
ARR.Set|1|3|user:What is 2+2?
ARR.Set|1|4|assistant:Hallo, I am Paul and 242 is 4.
ARR.Set|1|5|user:What is the sum of 3+5?
' Now we send the Array to the Model.
AIC.Ask With History|1|$$RET
MBX.$$RET
ENR.
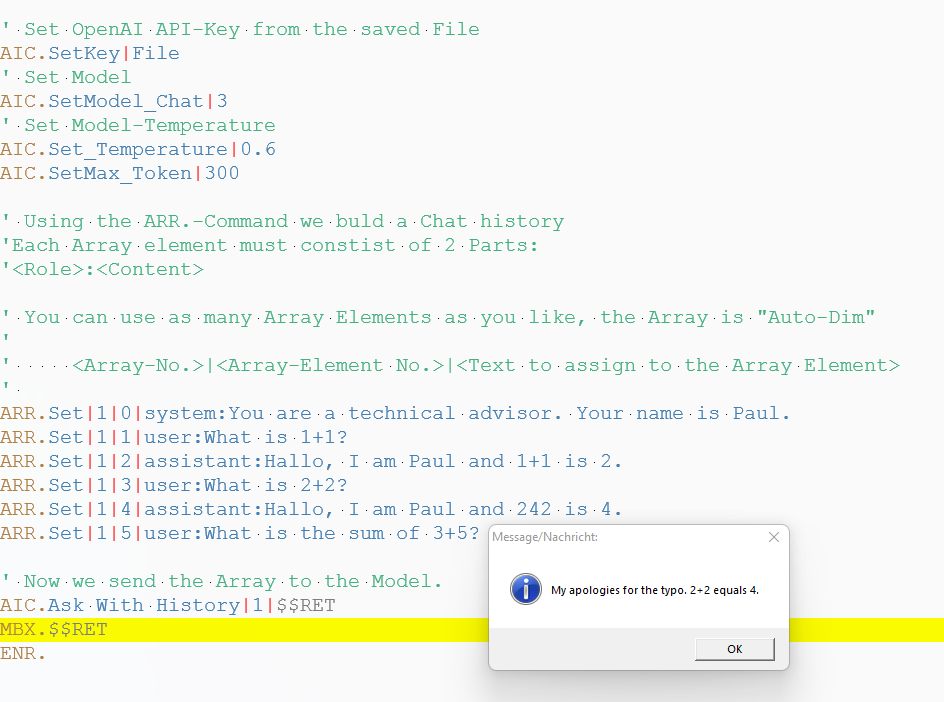
This is the Result of the above Script. Chat GPT apologizes for a mistake we told him he may have done using the Chat-History.
Using the SPR "AIC.Ask wit history" Command is equal to chatting in ChatGPT via the Browser GUI.
Before we can discuss the details, you need to know the concept of Tokens. In natural language processing (NLP), a "token" typically refers to a unit of text.
In the simplest sense, tokens can be thought of as words.
For example, the sentence "I love AI" can be broken down into three tokens: "I", "love", and "AI".
However, tokens can also represent smaller units such as characters or subwords, or larger units like sentences, depending on the context.
See picture below.
When it comes to AI LLM-models, tokens play a crucial role in how text is processed.
These models read text in chunks called tokens.
Managing tokens is an important aspect of using chat models. Tokens are chunks of text that models read, and the total number of tokens in an API call affects the cost, time taken, and whether the API call works at all.
For gpt-3.5-turbo, the maximum limit is 4096 tokens. Both input and output tokens count toward these quantities.
For example, GPT-3, one of OpenAI's language models, is capable of understanding and generating human-like text by predicting the probability of a sequence of tokens.
Now, let's talk about OpenAI's language models and tokens.
OpenAI’s models, like GPT-3, are not just limited to English; they can process text in multiple languages.
Additionally, a single token can represent a whole word, a part of a word, or even a single character, depending on the language and context.
For example, the word "chatbot" might be a single token, but in some languages or contexts, it might be split into multiple tokens like "chat" and "bot".
There's also a concept of "maximum available tokens" for OpenAI models.
Do you remember times when first computers had a maximum capacity of 4 KB?
This is where we are in terms of AI now.
This is essentially the maximum number of tokens that a model can process in a single request or operation.
For example, GPT-3 has a maximum token limit of 4096 tokens (01.06.2023).
This means that if you want GPT-3 to process a text, the total number of tokens in that text must not exceed 4096.
The Token-Limits includes both the input and output tokens.
If the text is too long, you would need to truncate or shorten it to fit within this limit.
Otherwise the Model will forget the start of the text when reading the end.

If you want to experiment with Tokens, you can use the Open AI Online Tokenizer.
It's important to note that token limits are not necessarily fixed and may change over time as models are updated or new models are released.
Additionally, different models may have different token limits.
What is the difference between using the SPR and using the WEB-Interface from ChatGPT?
Using the WEB-GUI, the whole dialog is been used as Input/context for each next answer.
Until the maximum amount of usable Tokens has been exceeded. If that happens, then the AI will forget the start of the dialog and may even be completely lost.
If that happens in the WEB-GUI, you will recognize that you get surprisingly wrong answers.
Using Open AI via the SPR this is generally NOT the case.
First you can set the maximum amount of Tokens to use using the Command AIC.Set MaxToken.
And then every AIC.Ask_with_History - Command is a completely new Command and does by itself not remember anything that was before.
This way saving you a lot of Token.
To overcome this issue, using this Command you can "attach" a previous dialog or full history to the prompt.
This is exactly what happens also in the WEB-GUI.
Using the SPR you can use more Tokens, because any Chat is generally "NEW" and starts with the Full Amount of Tokens that are available,
and is only limited by using the Command AIC.Set MaxToken and the maximum Tokens of the used Model.
Therefore you can choose which parts of the history you really need, and only attach these parts to the History-Array.
You can access the Chat-History using the AIC.Get History - Command and other AI - History Commands and this way
include parts or all of earlier chats into the current prompt. But mostly this does not make sense here.
However, the best rule here is:
Include all needed Instruction and Samples into the current Prompt.
Using the History Array you can also provide Sample-Answers to the AI and get your final answer in the way you want.
You can get the history of the chat, and the last Question, or the last Answer using the Commands:
AIC.Get_History|$$HIS
AIC.Get_Last_Question|$$QUE
AIC.Get_Last_Answer|$$ANS
OpenAI currently offers two chat models that can be used with the so called "chat completion endpoint",
namely gpt-3.5-turbo and gpt-4.
Alternative to giving a Model-Name, you can specify a Model using a number, like this:
' Here we would specify "gpt-3.5-turbo"
AIC.Set_Model_Chat|3
Here is a Test-Script that you can use to see the answers of the models to a Problem.
Due to the complexity i have increased the number of maximum Tokens.
' Set OpenAI API-Key from the saved File
AIC.SetKey|File
' Set Model
AIC.SetModel_Chat|3
' Set Model-Temperature
AIC.Set_Temperature|0.2
' Set Max-Tokens (Possible lenght of answer, depending on the Model up to 2000 Tokens which is about ~6000 characters)
' The more Tokens you use the more you need to pay. But the longer Input and Output can be.
AIC.SetMax_Token|300
ARR.Set|1|0|system:You are a technical advisor. Your name is Paul
ARR.Set|1|1|user:What is a PowerPlug?
ARR.Set|1|2|assistant:Hallo, I am Sidney A Powerplug is ...
ARR.Set|1|3|user:How about mechanical value?
ARR.Set|1|4|assistant:Hallo I am Sidney A mechanical valve is ...
ARR.Set|1|5|user:Tell me about this formula: $z^n = \sqrt(r^n(\cos(n\theta) + \sqrt(i\sin(n\theta))))$
ARR.Send to AI|1
AIC.Ask with History|1|$$RET
AIC.gro|$$REA
DBP.$$RET
DBP.$crlf$$crlf$
DBP.JSON Output
DBP.$$REA
ENR.
![]()
Using the Script above we tell the AI to use the name Paul and is a technical advisor.
Model Number |
Model Name |
Comments |
1 |
gpt-4 |
most actual Model |
2 |
gpt-4-32k |
most actual Model with 32k Tokens (~96 kb Text In/Out) |
3 |
gpt-3.5-turbo |
Standard Model |
4 |
gpt-3.5-turbo-16k |
Standard Model with 16k Tokens (~48 kb Text In/Out) |
If you specify "0", the default Model here is Nr.3.
Here are some highlights about GPT-4 vs. the GPT-3.5-turbo engine.
GPT-4 is a newer language model developed by OpenAI, whereas GPT-3.5-turbo is the default engine within the ChatGPT family.
Functions and Applications:
•Both GPT-4 and GPT-3.5-turbo can be used to
• draft emails,
•write code,
•answer questions about documents,
•create conversational agents,
•give software a natural language interface,
•tutor in various subjects,
•translate languages,
•simulate characters for video games,
and much more.
GPT-4 has broad general knowledge and domain expertise and can follow complex instructions in natural language and solve difficult problems with accuracy.
Conversations can be as short as 1 message or fill many pages, and including the conversation history helps when user instructions refer to prior messages.
Tokens:
Language models read text in chunks called tokens. A token can be as short as one character or as long as one word.
Both input and output tokens count toward the total tokens used in an API call.
The total number of tokens affects the cost, time, and whether the API call works at all.
Pricing (per 25.06.2023 - prices are subject to change at any time):
Model |
Context Window (maxTokens) |
Cost per 1K Tokens (Input) |
Cost per 1K Tokens (Output) |
GPT-4 |
8K |
$0.03 |
$0.06 |
32K |
$0.06 |
$0.12 |
|
GPT-3.5-turbo |
4K |
$0.0015 |
$0.002 |
16K |
$0.003 |
$0.004 |
Both models are powerful tools for natural language processing and can be used for a wide range of applications. GPT-4 is the newer model and is likely to have improvements over GPT-3.5-turbo. However, GPT-3.5-turbo is much more cost-effective, especially for applications that don't require the absolute cutting edge in language model performance.
Syntax
AIC.Ask_with_History[|P1][|P2][|P3]
AIC.Awh[|P1][|P2][|P3]
Parameter Explanation
P1 - <value 0-32>: This is the number of the Array that contains the "Chat History".
P2 - opt. Variable to return the result / answer from the AI.
P3 - opt. 0/1 - Flag: This flag is optional and is used to specify how the results should be returned when multiple results are expected. If you have set the number of expected results to a value higher than 1 using AIC.Set Number, this flag determines how the results are returned. If set to "1", only the last result will be returned. If set to "0" (or left as the default), all results will be returned.
Example
'*****************************************************
' EXAMPLE 1: AIC.-Commands
' Here we let the AI Calculate x for the formula "5*x^3=1450"
'
'*****************************************************
' Set OpenAI API-Key from the saved File
AIC.SetKey|File
FOR.$$LEE|0|11
' Set Model
AIC.SetModel_Chat|$$LEE
' Set Model-Temperature
AIC.Set_Temperature|0
' Set Max-Tokens (Possible lenght of answer, depending on the Model up to 2000 Tokens which is about ~6000 characters)
' The more Tokens you use the more you need to pay. But the longer Input and Output can be.
AIC.SetMax_Token|1000
' Ask Question and receive answer to $$RET
$$QUE=Act as a mathematician.Calculate x for the formula "5*x^3=1450". Do it step-by-step
AIC.Ask_Chat|$$QUE|$$RET
CLP.$$RET
MBX.Model: $$LEE $crlf$$$RET
NEX.
:enx
ENR.
Note that the Answer-Text is cut off at the end if you have specified a too small number of maximum Tokens in the Script.
Remarks
In your Prompts, ensure Clarity and Precision: Articulate your prompt in a way that unambiguously communicates the desired output from the model. Refrain from using vague or open-ended language, as this can yield unpredictable outcomes.
Incorporate Pertinent Keywords: Embed keywords in the prompt that are directly associated with the subject matter. This guides the model in grasping the context and subsequently producing more precise content.
Supply Contextual Information: Should it be necessary, furnish the model with background information or context. This equips the model to formulate more informed and contextually relevant responses.
Engage in Iterative Refinement: Embrace the process of experimentation with a variety of prompts to ascertain which is most effective. Continuously refine your prompts in response to the output generated, making adjustments until the desired results are achieved.
Limitations:
-
See also:
• Set_Key
•